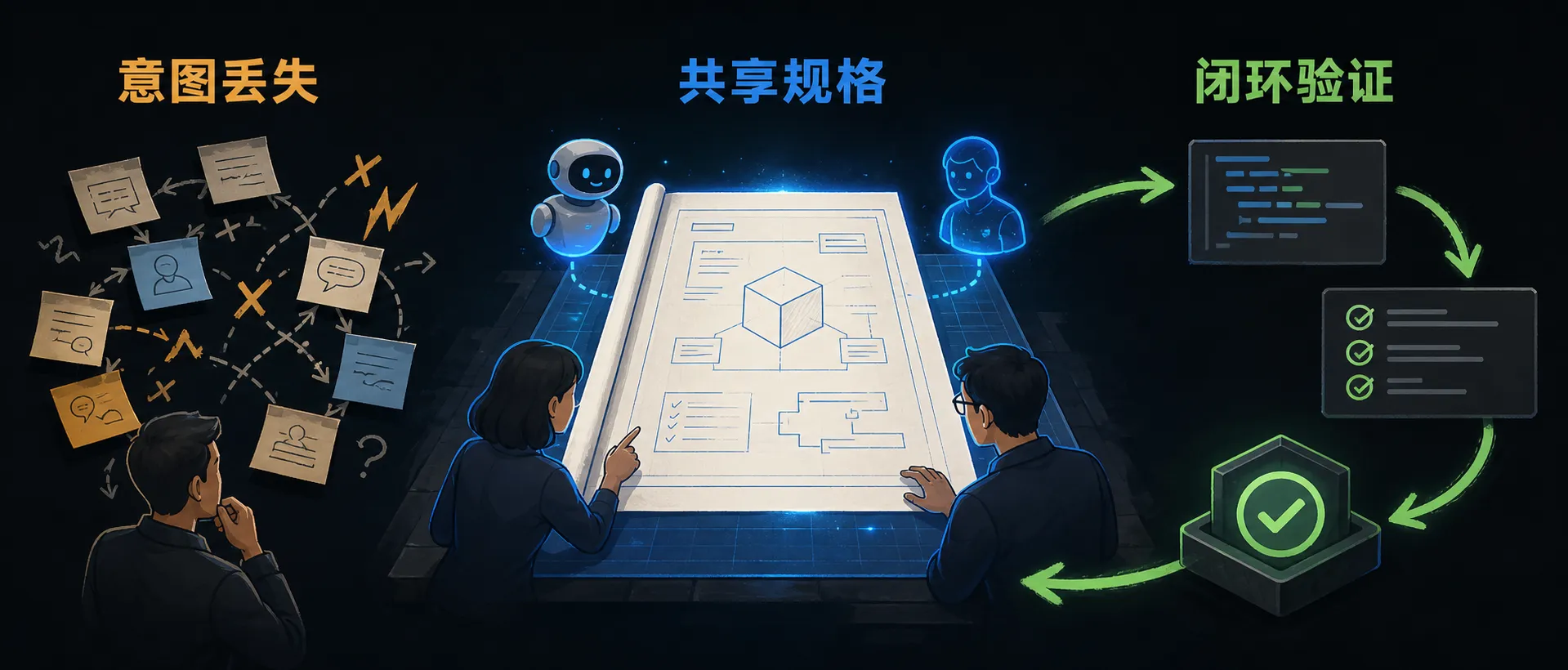
AI 让代码生成更快了,但快不等于交付结果更准。复杂项目里,真正容易出问题的地方不是某一段代码写得慢,而是需求、设计、实现、测试之间不断发生“意图丢失”。
Microsoft 这篇文章把 Spec-Driven Development(SDD,规格驱动开发)放到 AI 原生工程的语境里看:不要先写一堆 prompt 再事后对齐,而是先把意图写成可复用、可验证的规格,再让 AI 围绕这份规格生成代码、测试和配套产物。
问题不只是代码
AI-assisted development 已经能让团队更快完成局部任务,但很多团队仍会遇到一种熟悉的问题:软件能跑,甚至代码质量也不差,但最终结果和最初意图有偏差。
原文把这种偏差称为 translation loss,通常发生在四个交接点:
- stakeholder needs 到 product requirements。
- requirements 到 architecture and design。
- design 到 implementation。
- implementation 到 validation and release。
每一次交接如果只靠口头理解、临时 prompt 或分散文档,都会变成一次重新解释。AI 可以加速这些解释步骤,但它不能自动修正一开始没有澄清的歧义。
这也是 SDD 想解决的核心问题:让“意图”有一个持久载体,而不是在每次交接时重新猜。
Prompt-first 的边界
Prompt-first 工作流在小任务上很有效。改一个函数、生成一段脚本、解释一个 API,直接 prompt 往往最快。
问题会在范围变大后出现。需求、约束、边界情况如果只存在于一连串 prompt 里,团队得到的是很快的输出,但没有耐用的事实源。不同人、不同工具、不同会话对同一件事的理解可能逐步分叉。
原文列出的后果很具体:
- architectural drift:架构开始偏离原先约束。
- code drift:不同模块实现风格不一致。
- inconsistent implementations:相同规则在不同位置被写成不同版本。
- harder reviews:评审时很难判断代码到底应该满足哪份意图。
- rework:等发现假设不一致时,只能返工。
Spec-first 的改变在于:不是让 AI 从散落 prompt 中推断意图,而是团队先显式定义意图,再让 AI 基于结构化上下文执行。
SDD 是什么
Spec-Driven Development 是一种 spec-first 方法。团队先定义 guardrails、requirements、constraints、acceptance criteria 和 edge cases,再使用 AI 从这份共同上下文生成代码、测试和相关工程产物。
这里的 spec 不只是“需求文档”。它更像贯穿生命周期的连接组织:业务意图、架构设计、实现任务、测试验证都要能回到同一份规格上。
这点对 AI 编程尤其重要。AI 擅长在清晰上下文里执行,但不擅长替团队长期维护隐含共识。规格越清楚,AI 生成内容越容易被验证;规格越模糊,输出越快偏离。
原文最后用一句话概括得很直接:Spec quality = output quality。
团队会怎么变化
采用 SDD 后,团队投入精力的位置会前移。更多时间花在澄清意图和计划上,后面少一些返工。
产品经理不只是写一句需求,而是帮助定义场景和约束。架构师把这些意图转成规划模型。工程师用 AI 加速实现,但实现不再脱离规格。测试也更早介入,因为 acceptance criteria 从一开始就是显式的。
这不是把开发变慢,而是把模糊成本提前暴露。对于复杂项目,越晚发现歧义,修正成本越高。
Spec Kit 的角色
Microsoft 在文中提到 GitHub Spec Kit,它是把 SDD 落到日常工程流程里的工具包。它由 Microsoft 创建,开源,用来把需求转换成计划、实现任务和验证步骤,并适配 GitHub Copilot 等 AI coding tools。
Spec Kit 的工程生命周期可以简化成七步:
- Constitution:定义原则、标准和 guardrails。
- Specify:捕获需求、场景和 acceptance criteria。
- Clarify:解决歧义、依赖和边界情况。
- Plan:把意图转成架构、流程和约束。
- Tasks:拆成可实现的任务单元。
- Implement:用 AI 生成和迭代代码、测试。
- Validate:验证输出是否匹配规格。
这和仓库里已有的 Spec Kit 教程文章侧重点不同。那篇更像“工具怎么用”;Microsoft 这篇更强调为什么在 AI-native engineering 里需要这样的工作流:AI 越能快速执行,前置意图越要清晰。
三个实践锚点
原文给了几个实际团队经验,能帮助判断 SDD 不是只停留在方法论层面。
第一个是 brownfield 项目里的 asset type onboarding。团队发现新增资产类型的流程高度重复,但每次都要改 UI、API 和测试。后来他们把可复用模式写成 parameterized specs,每个新资产只记录差异点,逐步转向 configuration-driven model。结果是 onboarding 时间从 2-3 周缩短到几天。
第二个是大型 greenfield 平台。项目涉及 attendees、facilities、security、vendors、logistics、compliance 等领域,包含 thousands of moving parts。SDD 帮团队先围绕共享词汇、constitution、specs 和 plans 对齐,再扩展实现,从而减少跨服务一致性问题和执行 churn。
第三个是从 React + TypeScript 原型走向产品化。团队使用多个 agent 处理 DRI、Provisioning、Policy,还包括 connectivity health monitoring 和 admin dashboards。结构化 workflow 让团队更容易把 AI 生成结果和可见 UI 行为对照验证,并通过 custom prompts 和 quality-gate scripts 提高重复性。
这几个例子的共同点不是“用了某个工具就变快”,而是把重复模式、跨团队约束和验证标准写成了团队可以共同执行的规格。
先从小试点开始
Microsoft 的建议很克制:团队不需要一开始采用完整 SDD 生命周期。更好的方式是选一个对齐问题明显的小范围试点。
可以按四步走:
- Pilot:选择一个已有对齐痛点的功能或 workflow。
- Formalize:写一份轻量 spec,覆盖场景、约束和 acceptance criteria。
- Iterate:让 AI 从这份共享上下文生成实现产物。
- Refine and scale:把输出和 spec 对照评审,再调整流程。
这里有两个边界很重要。
不要一开始过度规格化。规格应该是 living artifacts,随着团队理解加深持续修正。也不要把所有小改动都拉进完整生命周期。SDD 的收益来自减少意图丢失,不是给每个任务增加流程负担。
什么时候值得用
SDD 更适合这些场景:
- 多角色参与,产品、架构、工程、测试需要共同理解同一目标。
- AI 参与的不只是代码片段,而是多文件、多模块、多步骤实现。
- 需求有明确约束、边界情况和验收标准。
- 已经出现过“做出来了,但不是要的东西”的返工。
- 同类功能会重复出现,值得沉淀成可参数化模式。
如果只是一次性脚本、小范围修补或很清楚的局部改动,直接 prompt 可能更经济。SDD 不是让所有开发都变成重流程,而是在复杂度足够高时给 AI 一个稳定的执行地基。
对 AI 原生工程的意义
过去谈 AI 编程,大家容易盯着“能不能生成代码”。现在更关键的问题变成:生成的代码是否忠实于团队意图,是否能被验证,是否能跨人、跨工具、跨阶段保持一致。
这就是 AI-assisted tasks 和 AI-native workflows 的差别。前者是把 AI 放进局部任务;后者要重新设计需求、规划、实现、验证之间的连接方式。
SDD 的价值不在于写更多文档,而在于把文档变成 AI 和人共同使用的工程接口。规格写得越像可执行上下文,而不是会后纪要,AI 才越可能稳定地产生可审查、可验证、可演进的输出。
如果你关注 AI 助手、开发工具和软件工程实践,可以关注 Aide Hub。这里会继续分享能落地的工具教程、技术观察和项目经验。