模块化单体架构中的内部与公共 API:控制混乱,成就高质量系统
在设计大型后端系统时,模块化单体架构(Modular Monolith)正成为越来越多.NET技术团队的首选方案。它既能享受单体应用的简洁部署,又能通过明确的模块边界提升可维护性。但关于模块之间的通信,你真的做对了吗?本文将结合实战经验,深入剖析内部 API 与公共 API 的区别、设计原则及落地细节,助你打造真正高质量的企业级系统。
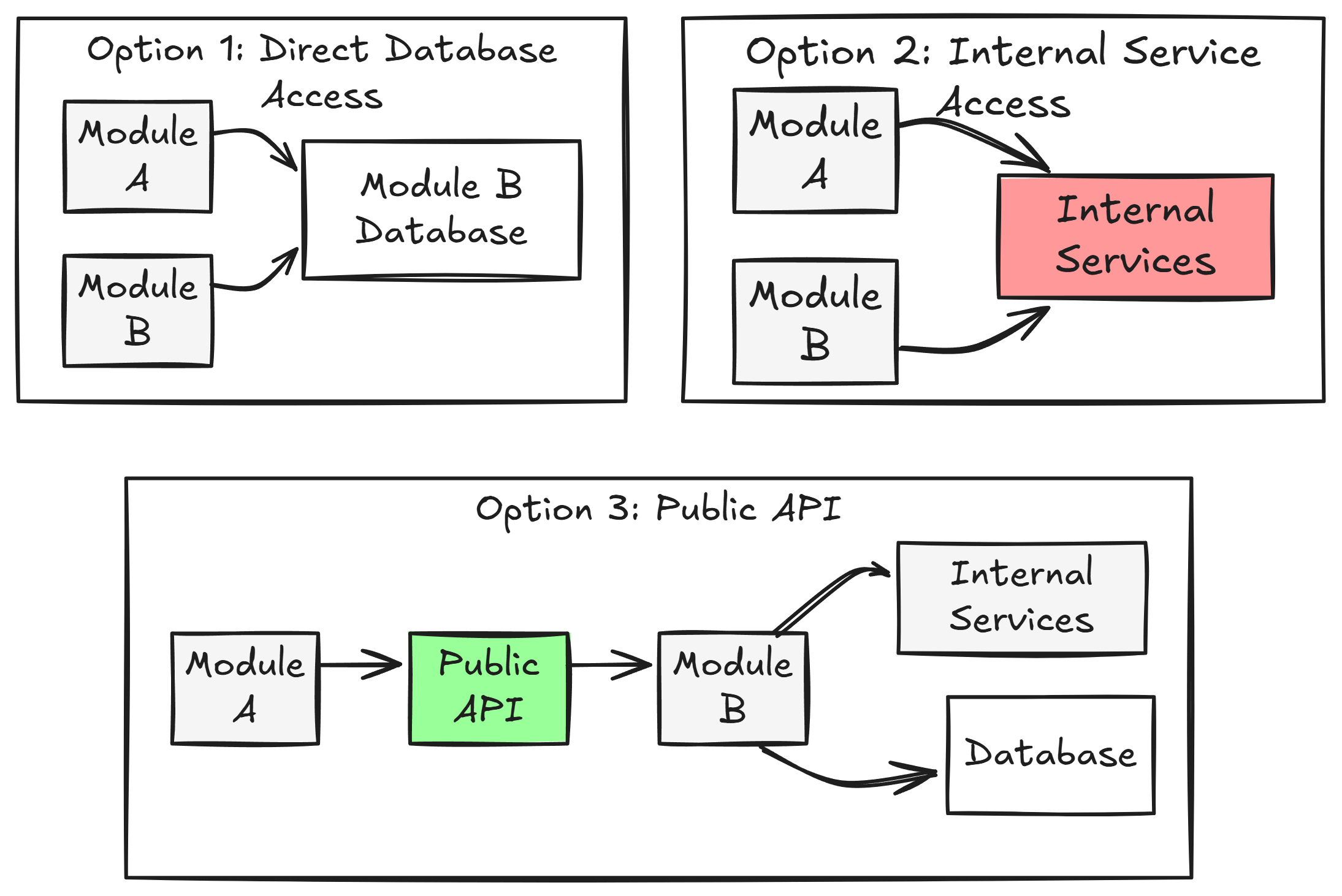
图1:模块间的三种常见通信方式
引言:为什么“公共 API”这么重要?
无数关于模块化单体的文章都在反复强调:“模块之间要用公共 API 通信”,但很少有人讲清楚——
- 为什么不能直接访问其他模块的数据或服务?
- 公共 API 到底解决了什么痛点?
- 具体应该如何设计?
随着我们系统规模扩大,如果没有合理的边界和契约,模块间自由耦合、数据库直连,最终将系统拖入不可维护的“泥潭”。公共 API,就是我们控制这种混乱、让依赖显性化的关键工具。
1️⃣ 模块间通信的现实:耦合无处不在,关键在于“可控”
首先要打破一个误区:公共 API 并不是为了消除耦合,而是让耦合可控。模块 A 需要用到模块 B 的能力时,有三种常见做法:
- 直接访问对方数据库(❌极易失控)
- 直接调用对方内部服务(❌隐式耦合)
- 通过公共 API 明确契约通信(✅推荐做法)
直接数据库访问和调用内部服务,看似方便,却会导致:
- 跨模块随意读取、修改数据,边界形同虚设
- 任意变更数据结构,影响全局,维护难度激增
采用公共 API,则可以:
- 显性声明依赖关系
- 避免“牵一发而动全身”的连锁反应
- 支持后续内部重构而不影响其他模块
📝 补充:即使采用异步消息通信,消息契约本质上也是一种“公共 API”。
进一步阅读:异步模块通信模式
2️⃣ 为什么需要公共 API?三大核心作用
① 契约定义(Contract Definition)
公共 API 明确声明了“别人可以对我做什么、不能做什么”,是边界的体现。
② 依赖管理(Dependency Control)
只有通过公共 API,依赖才是透明、可追踪的,否则系统复杂度难以把控。
③ 变更可控(Change Management)
只要保证公共 API 不变,内部可以随意重构,大大降低了维护成本。
代码示例:正确 vs. 错误的模块依赖
// 错误方式:Shipping 直接访问 Orders 的数据库
public class ShippingService
{
private readonly OrdersDbContext _ordersDb; // ❌ 强耦合
public async Task ShipOrder(string orderId)
{
var order = await _ordersDb.Orders
.Include(o => o.Lines)
.FirstOrDefaultAsync(o => o.Id == orderId);
}
}// 推荐方式:通过 IOrdersModule 公共 API 获取订单信息
public class ShippingService
{
private readonly IOrdersModule _orders;
public async Task ShipOrder(string orderId)
{
var order = await _orders.GetOrderForShippingAsync(orderId);
}
}3️⃣ 如何设计高质量的公共 API?
📌 暴露“用例”,而非“数据表”
- 不要直接暴露 CRUD 接口
- 要根据其他模块真实业务需求,定制专用接口
public interface IOrdersModule
{
// ❌ 通用CRUD(易滥用)
// Task<Order> GetOrderAsync(string orderId);
// ✅ 基于用例的接口
Task<OrderShippingInfo> GetOrderForShippingAsync(string orderId);
Task<OrderPaymentInfo> GetOrderForPaymentAsync(string orderId);
Task<OrderSummary> GetOrderForCustomerAsync(string orderId);
}📌 默认不对外开放,按需精细暴露
- 最开始保持所有内容私有,逐步按需开放
- 每次开放都需评估其必要性和未来维护成本
4️⃣ 数据保护与边界隔离的三板斧
即使有了公共 API,也不能掉以轻心。数据层面的隔离同样重要:
一、独立数据库 Schema
为每个模块分配独立的数据库 Schema,用权限隔离保证只能访问自己的数据。
CREATE SCHEMA Orders;
CREATE SCHEMA Shipping;
CREATE USER OrdersUser WITH DEFAULT_SCHEMA = Orders;
GRANT SELECT, INSERT, UPDATE, DELETE ON SCHEMA::Orders TO OrdersUser;二、独立连接字符串和 DbContext
为每个模块配置独立的数据库连接和 DbContext。
builder.Services.AddDbContext<OrdersDbContext>(options =>
options.UseSqlServer(builder.Configuration.GetConnectionString("OrdersConnection")));
builder.Services.AddDbContext<ShippingDbContext>(options =>
options.UseSqlServer(builder.Configuration.GetConnectionString("ShippingConnection")));🔍 延伸阅读:单应用中如何使用多个 EF Core DbContext
三、专用读模型 DTO
对外只暴露精简的只读模型(DTO),绝不暴露完整领域对象。
internal class Order { /* 内部完整模型 */ }
public class OrderShippingInfo // 对外只暴露必要信息
{
public string OrderId { get; init; }
public Address ShippingAddress { get; init; }
public List<ShippingItem> Items { get; init; }
}5️⃣ 跨模块查询怎么办?推荐事件驱动读模型
有些查询需求天然跨越多个模块(如“用户订单历史”),强行通过模块 API 拼凑并不可取。更优方案:
- 新建专门的查询模型(如 OrderHistoryModule)
- 用领域事件驱动同步各模块变化
- 查询时只读聚合好的数据
public class OrderHistoryModule
{
public async Task<CustomerOrderHistory> GetOrderHistoryAsync(string customerId)
{
return await _orderHistoryRepository.GetCustomerHistoryAsync(customerId);
}
}结论:让依赖显性化,拥抱可维护的未来
公共 API 并非万能钥匙,也不是为了杜绝一切依赖。它的真正价值,在于:
- 让依赖透明、可追踪、可维护 🧩
- 降低变更风险,提升团队协作效率 🔒
- 为系统演进预留空间,减少“技术债务” 🏗️
只有把控好这些细节,你的.NET模块化单体才能真正高内聚、低耦合,经得住大规模业务增长与技术迭代的考验。
💬 互动时间
你在实践模块化单体架构时遇到过哪些“混乱”的场景?你的团队又是如何处理模块间通信和依赖管理的?
欢迎在评论区留言讨论,也可以分享本文到你的技术群组,一起提升架构功力!