《Designing Data-Intensive Applications》深度解析与技术实践分享
“如果你想设计高可靠、可扩展、易维护的数据系统,这本书值得反复阅读。”——20年软件工程经验总结
引言
在大数据与分布式系统时代,如何设计高效、可靠、可维护的数据密集型应用(Data-Intensive Applications),成为了每一位中高级工程师、架构师无法回避的话题。Martin Kleppmann 的名著《Designing Data-Intensive Applications》(简称DDIA)以系统性、深刻性和前瞻性著称,被誉为“数据系统设计领域的圣经”。本文将结合实际工程经验,提炼其核心理论、关键技术点与落地建议,并穿插图示与案例,为广大技术人员提供一份实用的深度参考。
背景与意义
随着业务的复杂化和数据量的爆炸式增长,传统单体数据库和应用架构面临着可靠性瓶颈、扩展性难题和维护性挑战。DDIA 通过理论与实践结合,帮助我们理解为什么要这样设计数据系统、不同架构的权衡点在哪里、哪些方案适用于哪些场景。
适读人群:有3年以上开发/架构经验,参与过分布式系统、数据库或大数据平台建设的工程师与技术主管。
核心理念与技术原理
1. 数据系统设计的三大目标
DDIA 首先明确了数据系统的三大核心目标:
- 可靠性(Reliability):即使出现故障(硬件、软件、人为失误),系统也能正确运行。
- 可扩展性(Scalability):能够高效应对负载增长。
- 可维护性(Maintainability):便于运维和持续演进,包括可操作性、简洁性和可演化性。
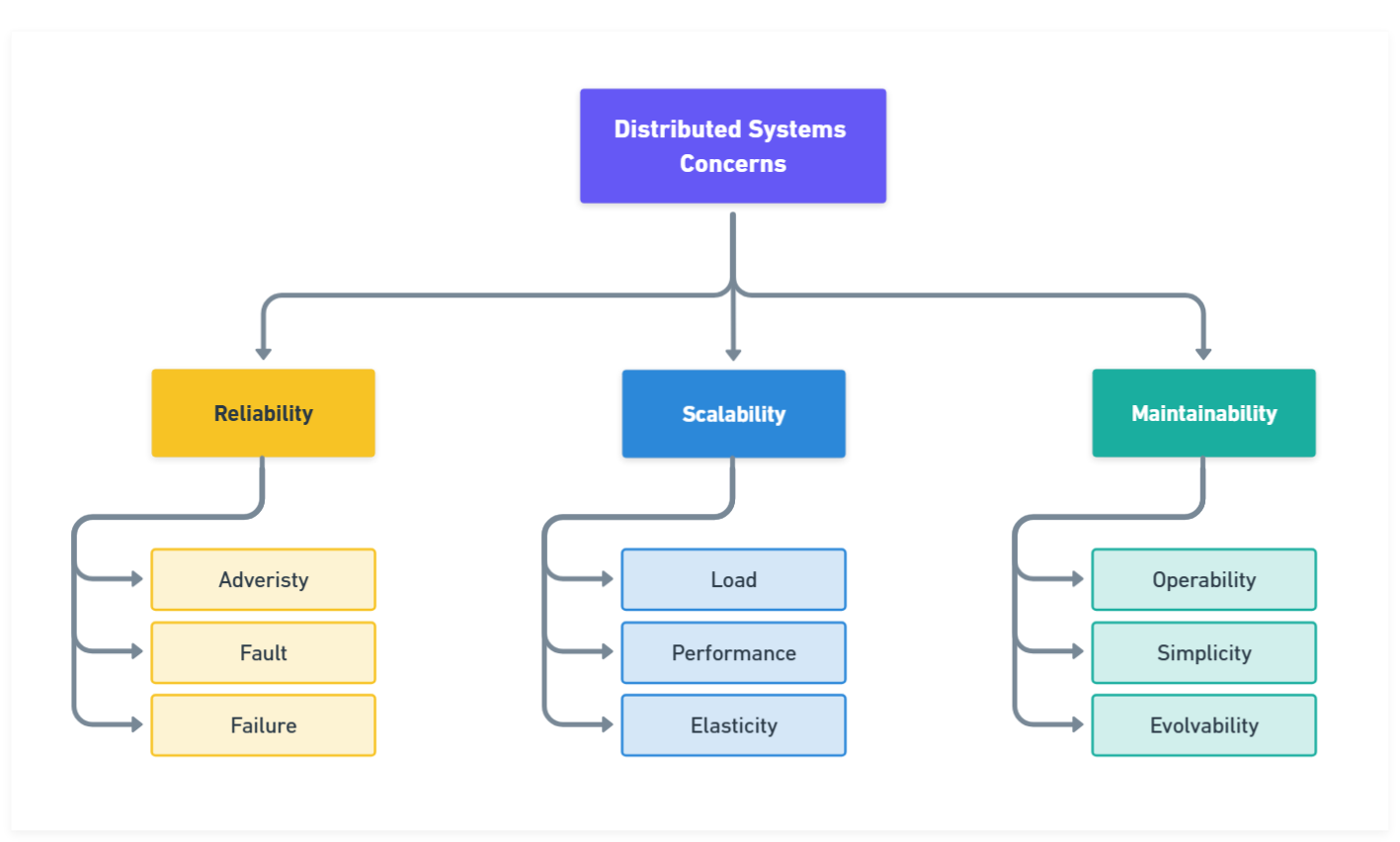
分布式系统关注点
2. 性能衡量——平均值并不可靠
性能分析时,不能只关注“平均响应时间”,而应关注P95、P99等分位数(Percentiles),即“长尾”用户体验。这是评估分布式系统性能瓶颈和优化方向的关键指标。
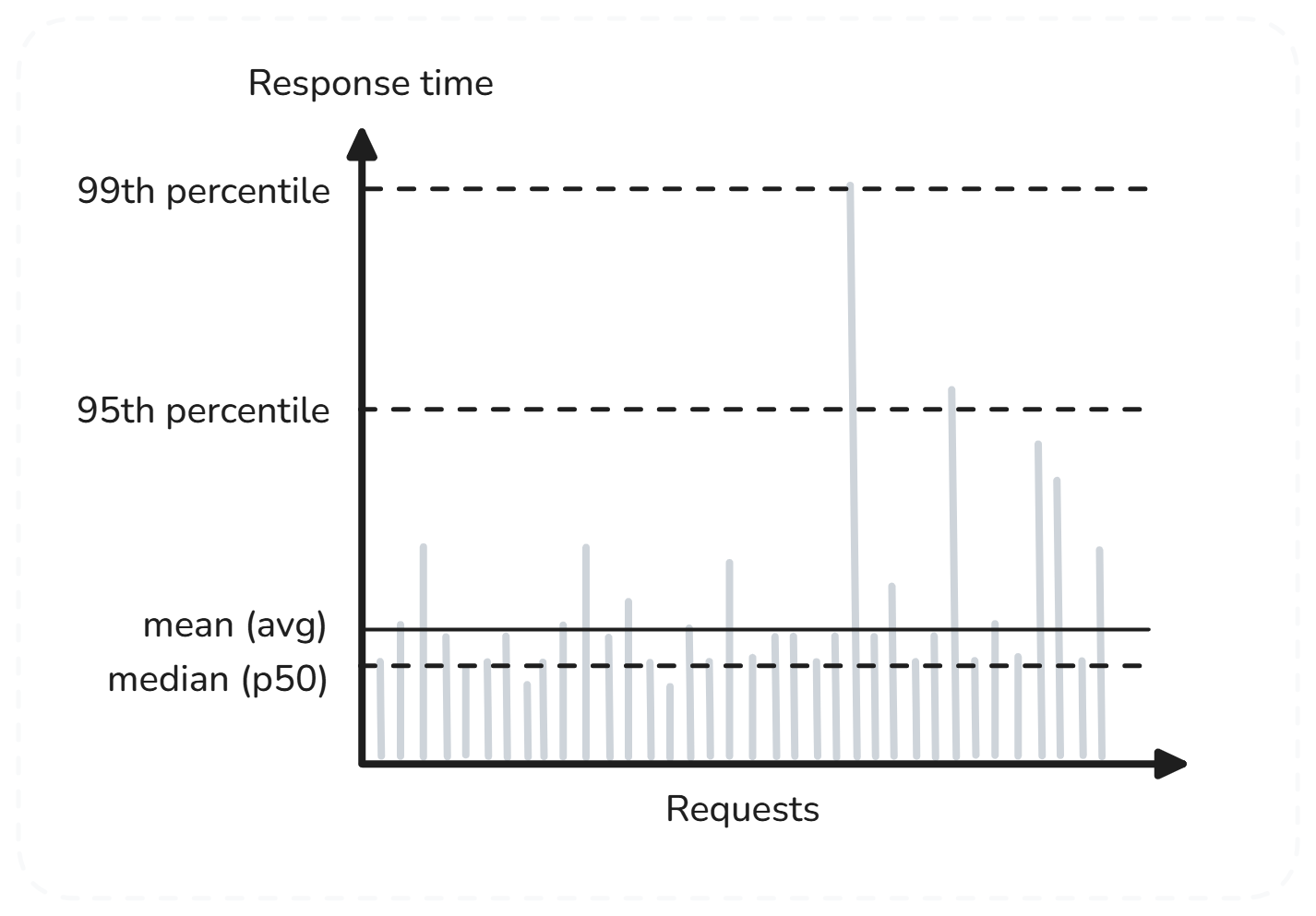
响应时间的不同分位数
3. 数据模型选择与场景适配
DDIA强调:选型要基于数据访问模式,而不是流行趋势!
- 关系型数据库(RDBMS):适合复杂查询、多表关联、强事务需求。
- 文档型数据库(Document DB):适合结构灵活、自包含的数据(如用户档案)。
- 图数据库(Graph DB):适合多对多、高度关联的数据(如社交网络)。
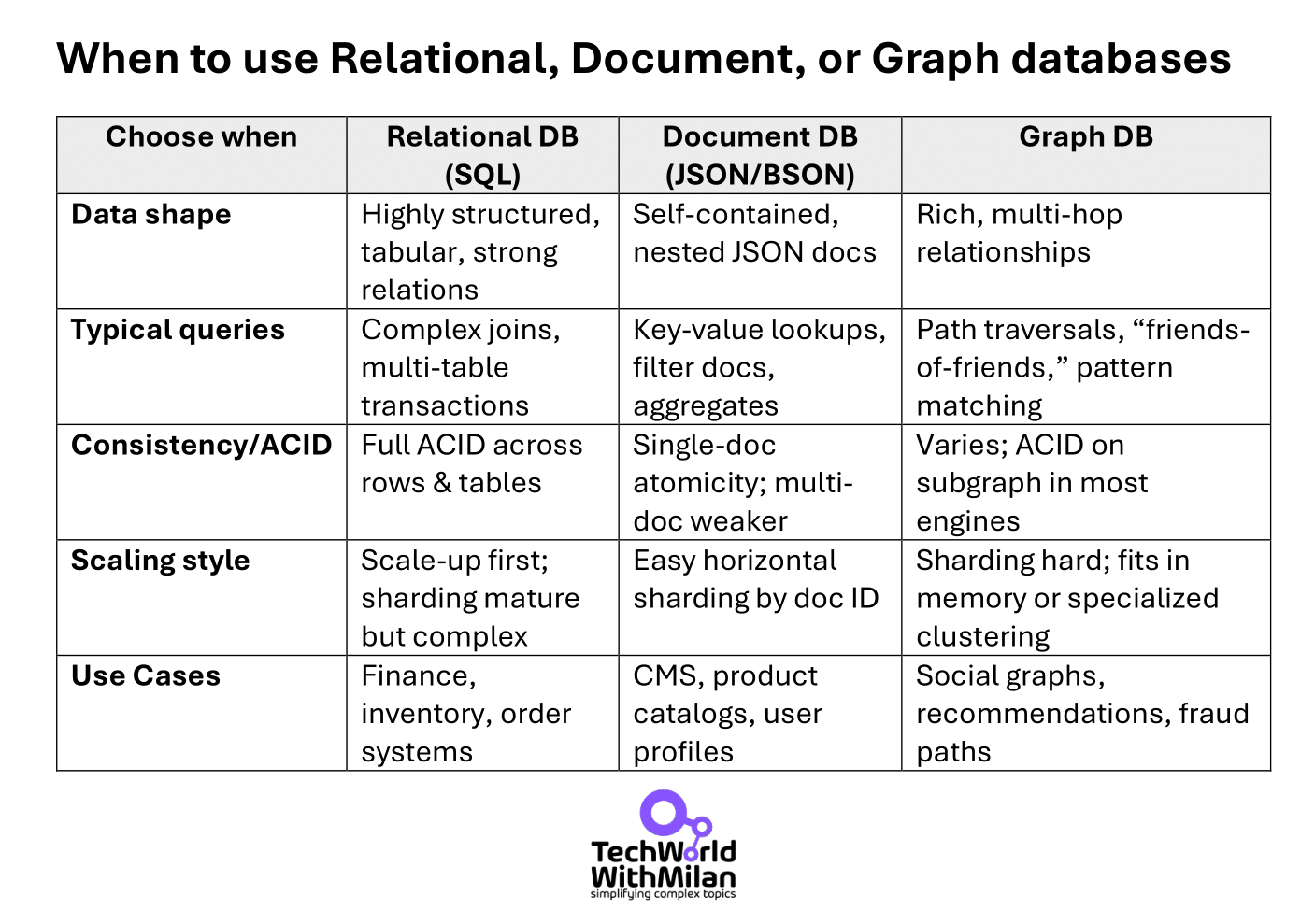
三种主流数据模型对比
4. 存储引擎内幕:B树 vs LSM树
- B树(B-tree):传统数据库主流索引结构,读性能优异,但随机写入较慢。适合读多写少场景。
- LSM树(Log Structured Merge Tree):现代NoSQL常用,极大优化写入性能,但读时需多层查找与合并。适合写多读少或高并发写入场景。
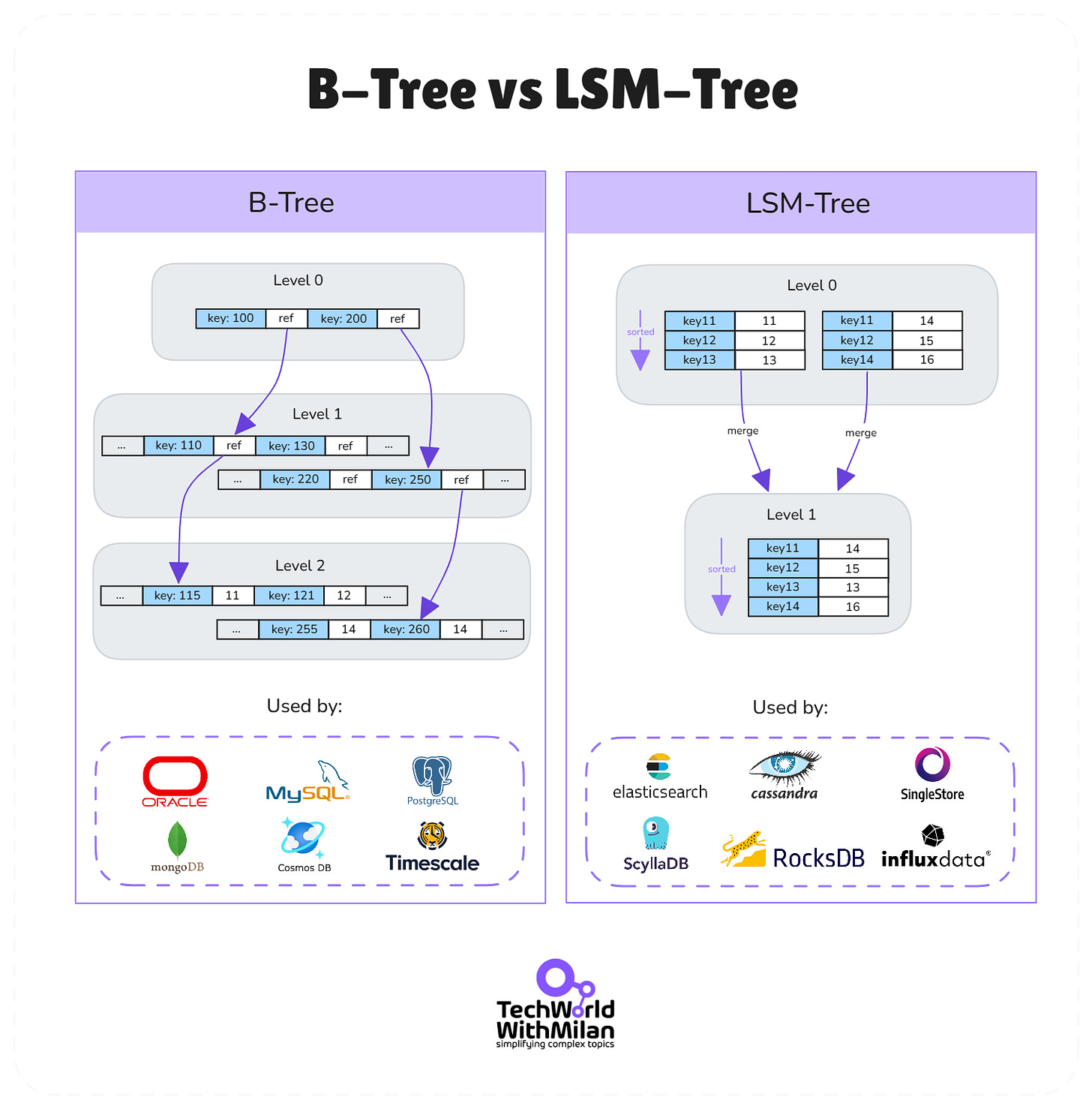
主流存储引擎结构及适用数据库一览
🔍 补充说明
布隆过滤器(Bloom Filter) 在LSM-tree架构中用于加速读操作,通过快速排除不存在的Key以减少磁盘IO。
5. 分布式系统核心机制
a) 数据复制(Replication)
主从复制(Single-leader)、多主复制(Multi-leader)、无主复制(Leaderless)三种模式,对应不同一致性、可用性和复杂度需求。
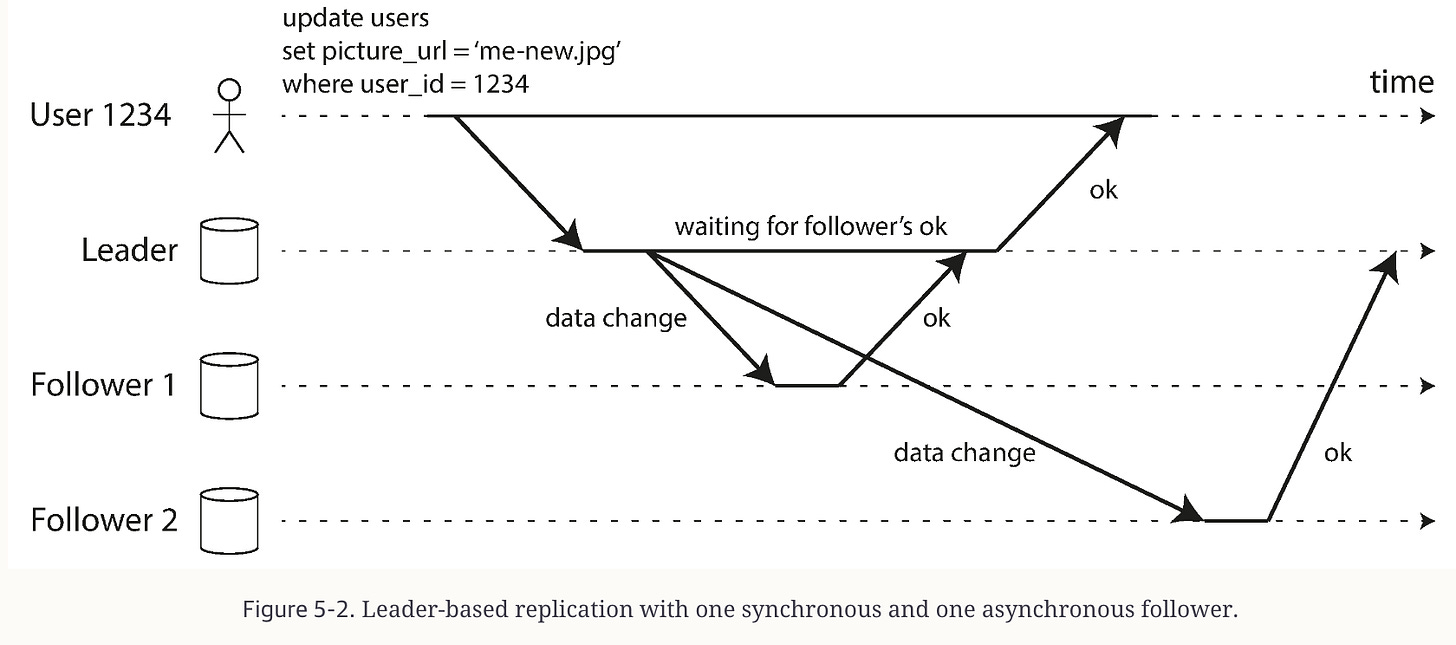
主从复制模型
b) 数据分片(Partitioning/Sharding)
- 哈希分片:均衡负载,便于横向扩展,但不利于范围查询。
- 范围分片:支持区间检索,但易出现热点问题。
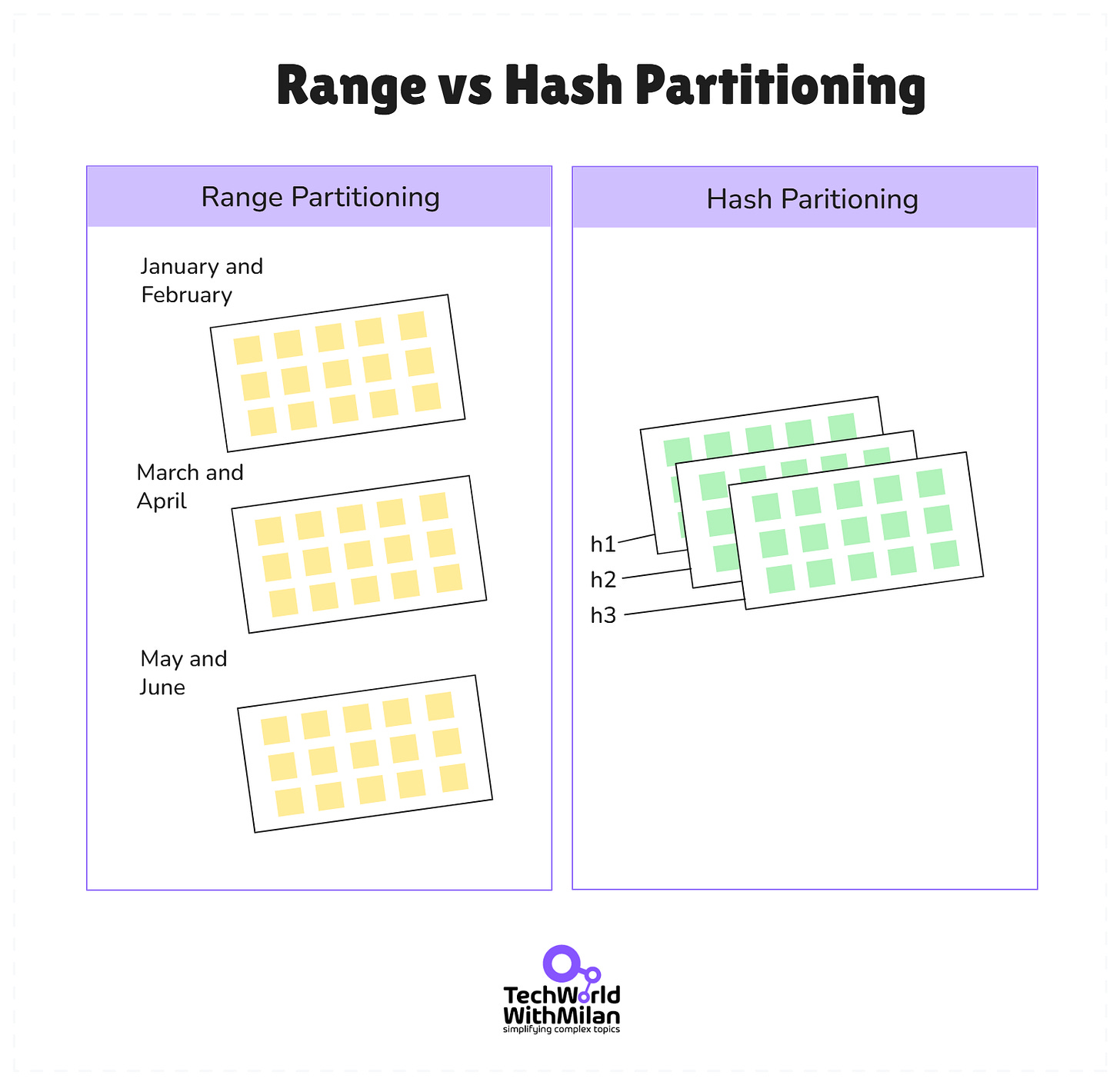
两种常见分片方式对比
c) 事务与一致性模型
- ACID事务与隔离级别(如Read Committed、Snapshot Isolation、Serializable),决定了并发操作下的数据正确性。
- CAP定理指出分布式系统无法同时满足一致性、可用性和分区容忍性三者,只能二选一。
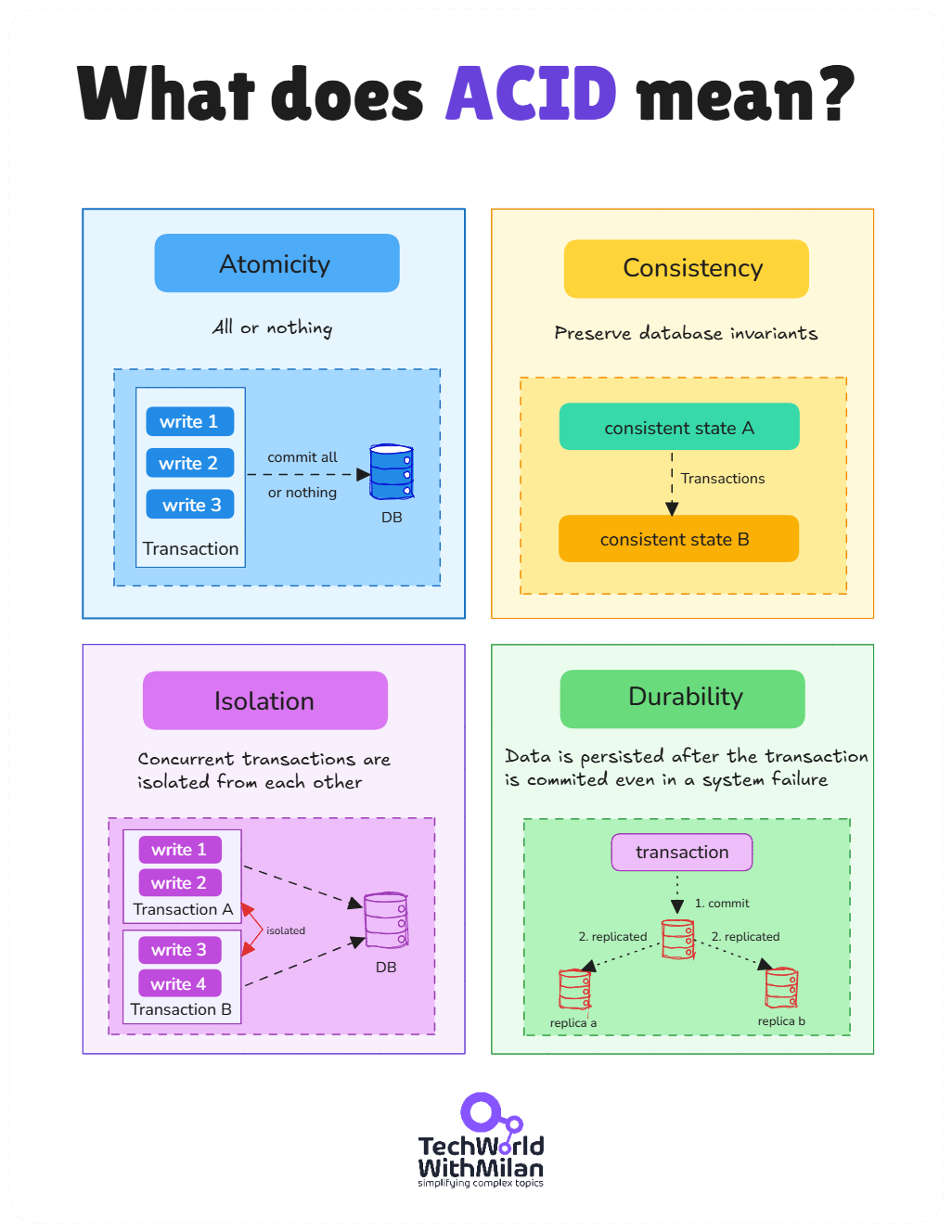
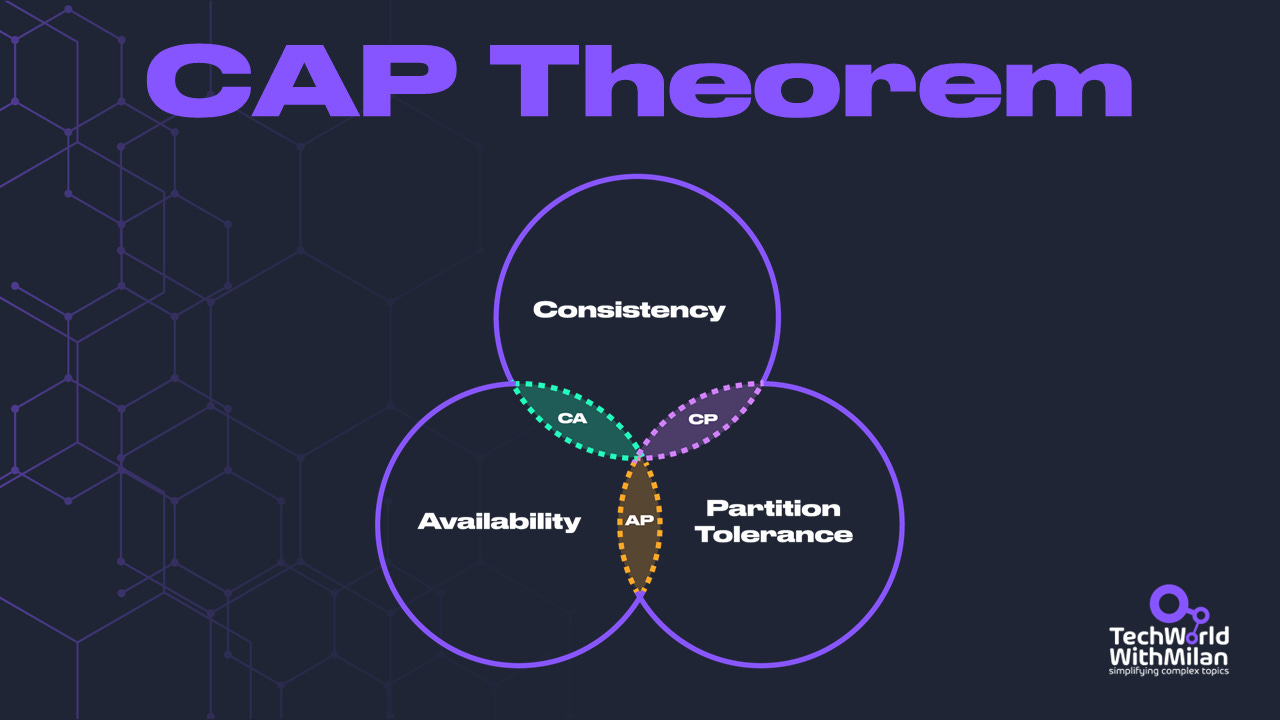
6. 批处理与流处理:实时与离线数据管道
批处理(Batch Processing)
一次性处理大批量数据,常用于定时统计、分析。MapReduce/Hadoop是代表技术。
流处理(Stream Processing)
实时处理事件流,如用户行为分析、监控告警。Kafka等消息队列支撑事件驱动架构。
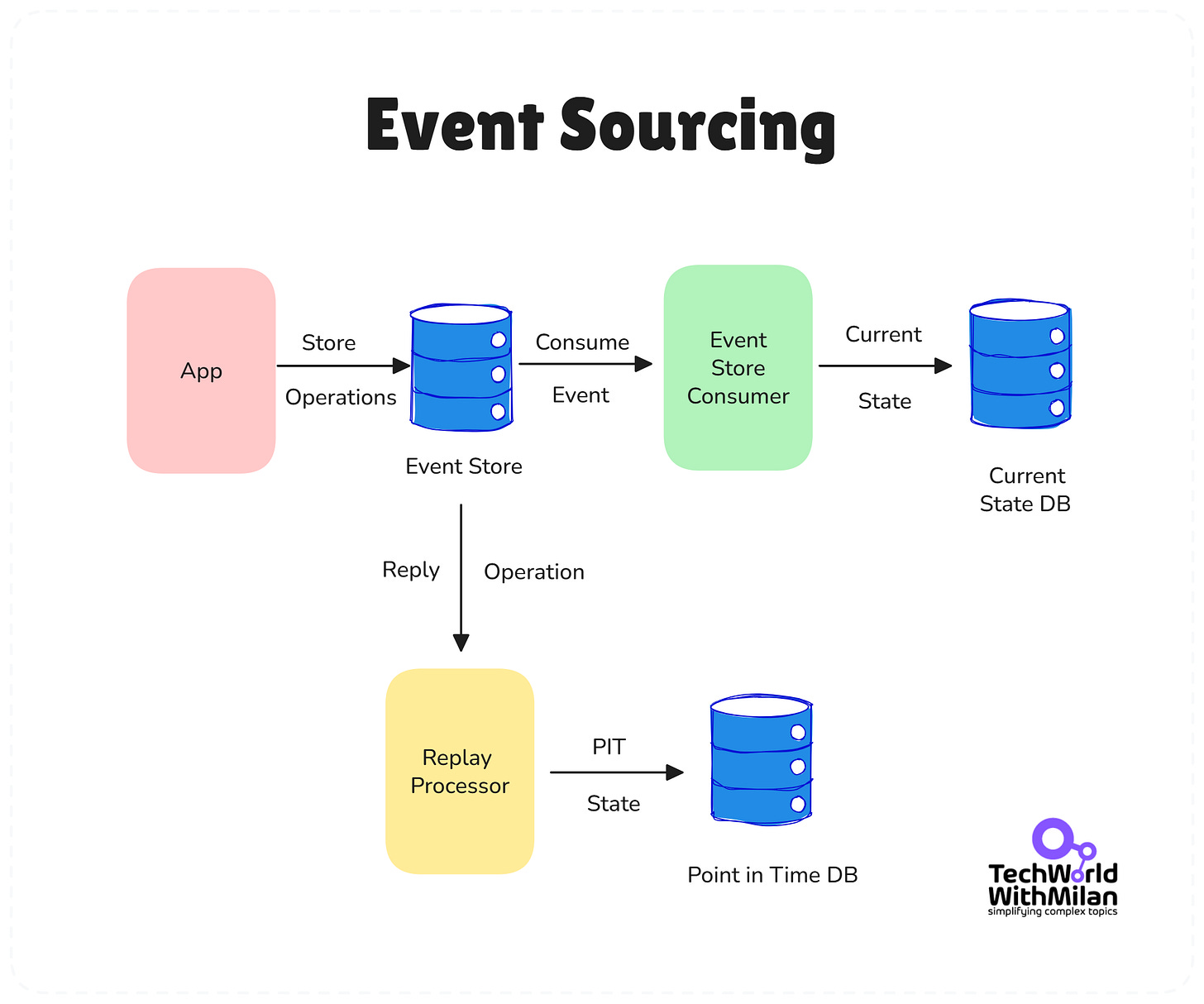
事件溯源架构示意
实践要点与架构决策清单
以下为DDIA作者和实践者总结的十大关键设计原则,便于架构师在项目中参考:

- 为失败而设计:假设任何组件都会出错,用冗余、重试和降级机制保障整体可靠。
- 关注有效指标:以P99延迟等分位数衡量性能,切勿只看平均值。
- 按需选型数据模型:业务需求决定是用关系型、文档型还是图型数据库。
- 理解底层存储机制:B树优读,LSM树优写。
- 清晰复制策略和一致性权衡。
- 合理分片并自动化运维。
- 审慎使用分布式事务,能不用就不用;跨服务协调首选Saga等弱一致方案。
- 拥抱事件驱动架构,实现服务解耦与弹性扩展。
- 重视可维护性和可演化性,提前规划监控、日志、Schema演进。
- 始终权衡并明确取舍——没有银弹方案。
实际应用案例解析
案例1:电商平台订单系统架构演进
- 初始单体MySQL数据库,订单量激增后出现性能瓶颈;
- 按订单ID做哈希分片,部分分片读写压力过大;
- 引入Redis缓存+消息队列解耦写入压力;
- 部分业务采用事件驱动架构,实现异步处理与最终一致性;
- 数据归档采用批处理,实时业务采用Kafka流处理。
案例2:社交网络朋友圈推荐引擎
- 关系型数据库难以高效表达“共同好友”等关系查询;
- 引入图数据库Neo4j,高效实现深层关系遍历;
- 采用事件溯源(Event Sourcing)记录用户行为,便于溯源与回放。
常见问题与解决方案
| 问题类型 | 解决思路 |
|---|---|
| 单点故障/高可用 | 多副本复制+自动故障转移 |
| 热点分区 | 优化分片键设计+负载均衡 |
| 跨分片事务一致性 | 弱化一致性需求,采用幂等操作或Saga补偿机制 |
| Schema频繁变化 | 使用文档数据库或Schema版本管理 |
| 长尾延迟问题 | 优化慢查询+前置缓存+聚焦P99指标 |
| 分布式锁竞争/死锁 | 尽量避免全局锁,用幂等设计或租约+唯一Token |
总结&思考
《Designing Data-Intensive Applications》不仅是一本理论书,更是分布式系统实战“武功秘籍”。它帮助我们建立起评估数据系统可靠性、扩展性、维护性的标准框架,并在面对复杂技术选型时学会冷静权衡利弊。
“最终你会发现,不同的技术方案没有绝对优劣,只有是否适合你的业务场景。”
强烈建议工程师在深入阅读DDIA之余,多思考自己业务的痛点,并将上述方法论应用到实际架构演进中。愿每一位工程师都能用科学的方法设计出真正高效可靠的数据系统!
延伸阅读&推荐资料
- Designing Data-Intensive Applications 官方网站
- 作者Martin Kleppmann课程与视频频道
- Database Internals - 深入数据库底层实现
- 我的Notion读书笔记整理
- Understanding Distributed Systems
如果你已读过DDIA,不妨留言分享你的“aha时刻”!