短结论:大多数 .NET 团队在 2026 年不需要仓储模式。DbContext 已经是 Repository + Unit of Work 的实现,Microsoft 自己的架构文档也这样说。在它上面再包一层 IUserRepository,是用抽象包抽象,没有新增任何行为。
原文作者在 50+ 个 .NET API 项目中,能用一只手数清楚真正值回票价的场景。其余 95% 的时间,仓储层只是减慢了开发速度,把有用的 EF Core 特性藏在不灵活的方法签名后面,而那个”以后可以换 ORM”的承诺,一次都没有兑现过。
仓储模式是什么
仓储模式(Repository Pattern)最早由 Martin Fowler 在 2002 年的《企业应用架构模式》中提出,当时 .NET 数据访问意味着手写 ADO.NET、手动管理连接、逐行映射 DataReader。在那个年代,它的两个目标都有意义:把业务逻辑和数据访问解耦,以及让数据访问可以被 mock。
在 .NET 代码里,一个典型的仓储长这样:
public interface IUserRepository
{
Task<User?> GetByIdAsync(int id, CancellationToken ct);
Task<List<User>> GetAllAsync(CancellationToken ct);
Task AddAsync(User user, CancellationToken ct);
void Update(User user);
void Remove(User user);
Task SaveChangesAsync(CancellationToken ct);
}问题在于,这两个目标在 EF Core 10 里都已经被框架本身解决了。DbContext 就是 Unit of Work,DbSet<T> 就是每个实体的类集合仓储接口。Microsoft 在自己的微服务架构指南里明确写道:“Entity Framework DbContext 类基于 Unit of Work 和 Repository 模式,可以直接在代码中使用。“
5 个常见理由,逐一拆解
理由一:“这样可以和 EF Core 解耦”
最强版本的说法是:“如果哪天要换成 Dapper 或 RavenDB,仓储层能保护我们不用全部重写。”
在实践中,这几乎从来不会发生。50+ 个项目,一次主 ORM 替换都没有过。最接近的情况是把 Dapper 加进来处理少数热点读路径——但这不需要仓储抽象,因为是并行使用两个工具,不是替换。
更大的问题是抽象会泄漏。一旦仓储暴露 IQueryable<T>,调用方链式调用的每个 Where()、Include()、Select() 都在使用 EF Core 的表达式树语义。换了 Dapper,每个调用点都会出问题。你没有真的解耦,只是通过 IQueryable<T> 的后门把 EF Core 语义引进来了。
如果仓储隐藏了 IQueryable<T>,只暴露 Task<User?> 方法,泄漏是修了,但分页、投影、Include 和动态过滤都没了。于是一次性方法开始堆积:GetUsersByEmailAndStatusOrderedByCreatedAtAsync、GetActiveUsersInTenantWithRolesAsync……仓储变成了一个到处是重载的方法墓地。
结论:解耦论证失败两次——ORM 几乎不会被换,而一旦抽象”足够好”到能换,它已经失去了大部分表达力。
理由二:“为了可测试性”
论点:mock IUserRepository,单元测试服务层,快速反馈,自信发布。
不需要仓储也能做到这些。EF Core 10 提供了 IDbContextFactory<TContext> 用于在测试中创建并行的 DbContext 实例。.NET 的 Testcontainers 可以在 CI 中运行真实的 PostgreSQL 或 SQL Server,类级初始化开销约 1-2 秒。
mock 仓储测试的是一件事:服务层的编排逻辑。它测不到 LINQ 查询能否翻译成有效 SQL、join 是否返回正确结构、Include() 是否产生笛卡尔积爆炸、事务边界是否正确。这些才是真正会流到生产环境的 bug。原文作者亲历了 4 个 bug 在绿色 CI 中通过了 mock 仓储的单元测试,然后在生产炸掉:一个缺少的 Include()、一个 C# 里正常但 SQL 里不正确的字符串比较、一个 EF Core 无法翻译的 OrderBy、一个和 Include() 组合后爆炸的 Distinct()。
结论:用 mock 仓储测试的是错误的层。用 IDbContextFactory<TContext> 加 Testcontainers 测试真实的数据访问,才能抓住那些会真正出问题的 bug。
理由三:“集中管理可复用查询”
这是最有道理的一条。查询逻辑的重复是真实存在的。但有比仓储更轻量的替代方案:
IQueryable<T> 扩展方法 — 查询可发现、可链式调用、可组合:
public static class UserQueries
{
public static IQueryable<User> ActiveOnly(this IQueryable<User> source) =>
source.Where(u => u.IsActive && !u.IsDeleted);
public static IQueryable<User> InTenant(this IQueryable<User> source, Guid tenantId) =>
source.Where(u => u.TenantId == tenantId);
public static IQueryable<UserDto> ToDto(this IQueryable<User> source) =>
source.Select(u => new UserDto(u.Id, u.Email, u.FullName));
}用法:
var users = await dbContext.Users
.ActiveOnly()
.InTenant(tenantId)
.ToDto()
.AsNoTracking()
.ToListAsync(ct);一次 SQL 往返,只查 DTO 需要的列。没有 IUserRepository 接口需要维护,没有额外项目需要注册到 DI,没有随时间膨胀的 bool 参数。
结论:用组合而不是接口来集中查询逻辑。
理由四:“对外隐藏 EF Core 复杂度”
论点:让初级开发者不用学 DbContext 的生命周期、变更追踪、Include 链、投影规则。
实际上仓储永远包得不够好。早晚有人需要 .AsNoTracking() 用于读路径,需要 .Include(x => x.Roles) 获取关联实体,需要 .ExecuteUpdateAsync() 做批量操作。于是 bool 参数出现:bool tracking = true、bool includeRoles = false。然后是选项对象:GetByIdAsync(int id, UserIncludeOptions opts)。最终出现一个没人能用一句话描述的 GetByIdWithEverythingAsync。
你的”抽象”变成了一个词汇更差的 EF Core。初级开发者还是要理解变更追踪,只不过是通过一个自定义包装器而不是有将近十年文档、示例和社区知识的框架。
结论:EF Core 是一个公开的、有完善文档的 API。包装它会让上手变得更难,不是更容易。
理由五:“Microsoft 推荐这样做”
被引用最多、被误读也最多的论据。Microsoft 的微服务电子书确实提到了仓储模式,但原文的立场比大多数人记得的更平衡。原文写道:“DbContext 类基于 Unit of Work 和 Repository 模式,可以直接在代码中使用……在需要最简单代码的情况下,你可能直接使用 DbContext 类,就像许多开发者做的那样。”
这个建议只在”复杂微服务或应用”中推荐自定义仓储——即领域层必须与持久化基础设施解耦的场景。
如果你的应用是一个与单个关系型数据库交互的分层 CRUD API,你处于 Microsoft 自己推荐”最简单代码”的场景,而不是”复杂微服务与聚合根”的场景。
3 个真正需要仓储的场景
仓储模式没有死,只是被过度使用了。有 3 个具体场景下,作者还是会毫不犹豫地建它。
1. 严格 DDD + 聚合根
当领域模型有明确的聚合边界和必须在聚合内部强制执行的不变量时,每个聚合根对应一个仓储是正确的工具。这里仓储的目的不是包装 EF Core,而是确保聚合外的代码无法绕过根直接加载或修改聚合内的实体。
public interface IOrderRepository
{
Task<Order?> GetByIdAsync(OrderId id, CancellationToken ct);
Task AddAsync(Order order, CancellationToken ct);
}没有 GetAll(),没有 IQueryable<Order>。读取被有意限制,因为聚合是写边界。报表和列表走独立的读模型(CQRS)。
2. 领域层不能引用 EF Core(Clean Architecture)
当领域项目(例如 MyApp.Domain)被禁止引用 Microsoft.EntityFrameworkCore 时,你需要在 Domain 里定义 IUserRepository 接口,在 Infrastructure 里提供实现。这是标准的 Clean Architecture / Onion / Hexagonal 模式。仓储接口是端口,EF Core 是背后的适配器。
这是最能自圆其说的非 DDD 仓储使用场景,因为接口强制执行了一条真实的架构规则:领域层独立于框架。
3. 多个数据源对应一个逻辑实体
当 User 的数据分布在 PostgreSQL(个人资料)、MongoDB(偏好设置)和 Redis(会话状态)中,而应用的其余部分不应该知道这些时,仓储是正确的接缝。它把多源持久化策略隐藏在统一接口背后——这才是仓储模式最初被设计出来要解决的问题。
应该跳过仓储的 5 个场景
- 分层 CRUD API,单数据库:这是 80% 的场景。在 handler、service 或 endpoint group 里直接用 DbContext。
- 没有 DDD 需求的新项目:如果没人在主动建模聚合,不要提前构建这个抽象。
- 读密集的报表和分析 API:这类场景需要投影、join、动态过滤和临时查询形状,仓储会在每个 endpoint 都和你作对。
- 小团队(1-5 人):抽象层的认知和维护成本需要理解其存在原因的维护者,小团队的精力最好用来发货功能。
- 带独立读模型的 CQRS:读操作投影到视图模型,不是聚合,每个实体一个仓储和系统形状不匹配。
现代替代方案:薄查询处理器
不少团队坚持仓储模式,是因为他们没有看到没有它的代码长什么样。
仓储包装版:
public sealed class GetUserHandler(IUserRepository repo)
{
public async Task<UserDto?> Handle(int id, CancellationToken ct)
{
var user = await repo.GetByIdAsync(id, ct);
return user is null
? null
: new UserDto(user.Id, user.Email, user.FullName);
}
}薄处理器版,无仓储:
public sealed class GetUserHandler(AppDbContext db)
{
public Task<UserDto?> Handle(int id, CancellationToken ct) =>
db.Users
.Where(u => u.Id == id)
.Select(u => new UserDto(u.Id, u.Email, u.FullName))
.AsNoTracking()
.FirstOrDefaultAsync(ct);
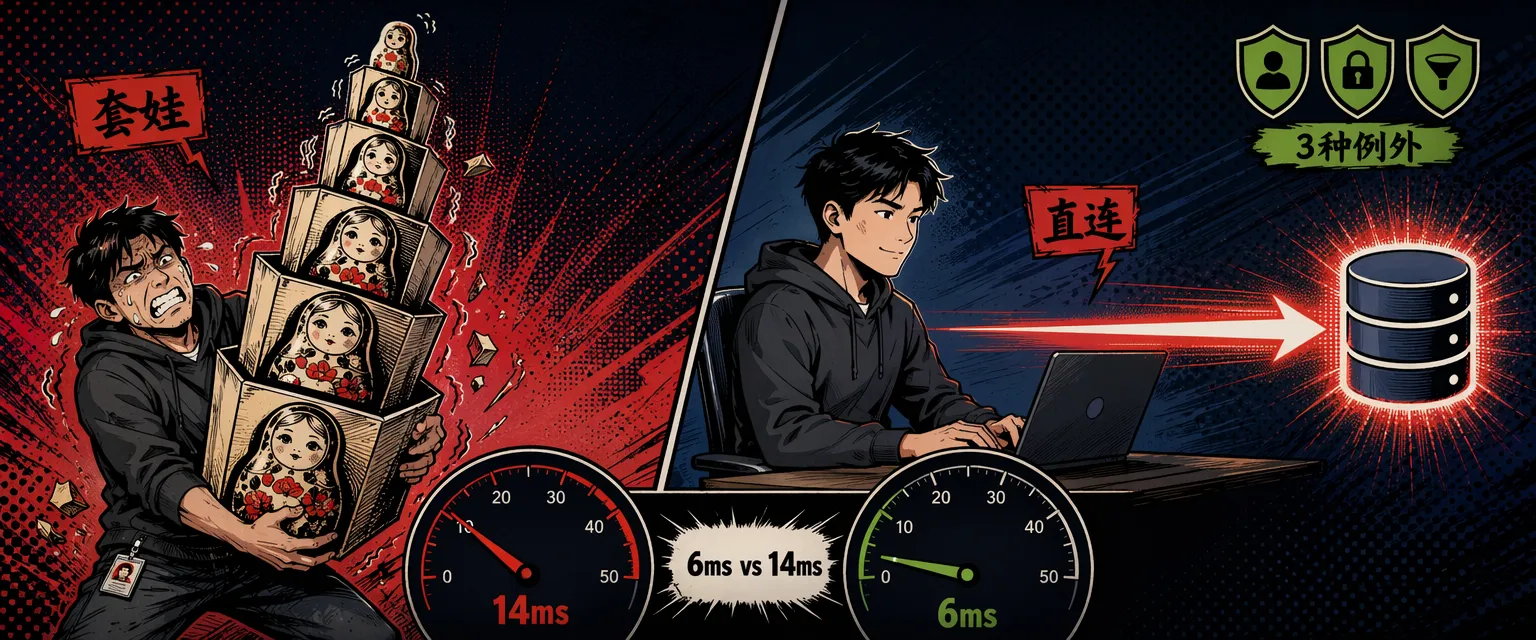
}薄处理器更短,但优势不只是行数。这是实测数据带来的机械差异:
- 投影在 SQL 里执行:薄处理器只查 3 列。仓储版加载完整 User 行(表上的每一列),在内存里物化后再构建 DTO。在有 20 列(包括一个 TEXT 简介字段)的 User 表上,仓储版多传了 38% 的字节,中位查询时延从 6ms 升到 14ms(PostgreSQL 17 + .NET 10)。
- 读操作无变更追踪:
AsNoTracking()就在调用点上,一目了然。 - 针对真实数据库可测试:用基于
IDbContextFactory<AppDbContext>的 AppDbContext 配合 Testcontainers PostgreSQL 实例注入,测试覆盖真实 SQL 翻译,而不是一个假装是仓储的 mock。 - 新增查询零仪式感:需要新查询?写一个新 handler,不需要接口、不需要实现、不需要 DI 注册、不需要第二个项目。
写操作同样适用:
public sealed class CreateUserHandler(AppDbContext db)
{
public async Task<int> Handle(CreateUserCommand cmd, CancellationToken ct)
{
var user = new User(cmd.Email, cmd.FullName);
db.Users.Add(user);
await db.SaveChangesAsync(ct);
return user.Id;
}
}DbContext.SaveChangesAsync() 就是 Unit of Work。你不需要再写一个 IUnitOfWork 类。
决策矩阵
| 场景 | 用仓储 | 直接用 DbContext |
|---|---|---|
| 分层 CRUD API,单数据库 | ❌ | ✅ |
| 严格 DDD + 聚合根 | ✅ | ❌ |
| 领域层不能引用 EF Core(Clean Architecture) | ✅ | ❌ |
| 多个数据源对应一个逻辑实体 | ✅ | ❌ |
| 带独立读模型的 CQRS | ❌ | ✅(薄处理器) |
| 读密集的报表/分析 endpoint | ❌ | ✅ |
| 1-5 人小团队,快速迭代 | ❌ | ✅ |
| 需要隔离测试数据访问 | ❌(用 IDbContextFactory + Testcontainers) | ✅ |
| 以后可能换 ORM | ❌(IQueryable 抽象会泄漏) | ✅ |
| 集中管理查询过滤和投影 | ❌(用 IQueryable 扩展方法) | ✅ |
仓储列是 ❌ 就意味着你在为一个成本具体、收益理论上的抽象付费。
已有仓储怎么办
如果代码库里已经有仓储层,不要恐慌删除。抽象的成本是真实的,但有上限;半迁移状态比任何一种纯状态都更糟糕。逐功能增量迁移——每个新的垂直切片直接用 DbContext,已有仓储保持不动。6-12 个月后,仓储的表面积会自然收缩。
关键结论
- DbContext 在 EF Core 10 中已实现 Unit of Work 和 Repository 模式,Microsoft 的架构指南明确说明可以直接使用
- “以后可以换 ORM”几乎从来不会发生,而当抽象”好到能换”时,它已经通过
IQueryable<T>泄漏了 EF Core 语义 - mock 仓储测的是错误的层,
IDbContextFactory<TContext>+ Testcontainers 用更少的仪式感提供更好的覆盖 - 用
IQueryable<T>扩展方法或规格模式集中可复用查询,不要用仓储接口 - 只有 3 个场景值得建仓储:严格 DDD + 聚合根、Clean Architecture 中持久化无关的领域层、多数据源合并
- 薄处理器直接投影到 DTO,比仓储包装的读操作快:原文实测中位响应时延大约减半,多传字节数降低 38%